Revenue operations
Gong’s topic detection technology is issued a patent

Eilon Reshef
Chief Product Officer & Co-Founder at Gong
Published on: May 6, 2020
Today, the US Patent and Trademark Office issued patent #10,642,889 titled “Unsupervised automated topic detection, segmentation and labeling of conversations”, which protects our technology for understanding topics in customer conversations.
I thought it would be useful to the essence of the technology, and how it came about.
The goal: understanding conversations beyond keywords
When we started Gong, we wanted to give customer-facing teams visibility into their customer conversations—calls, emails, text messages, and any other method in which sellers are communicating with their buyers.
To do this, we realized we needed technology that can understand interactions with customers.
The main method available at the time was based on keywords. Many first-generation technology players were trying to provide so-calledspeech analyticssolutions to the call center space, mostly based on keywords.
But, to truly understand conversations, we quickly realized this approach is fundamentally lacking.
For example, to understand whether someone talks about pricing, one may be tempted to try out all the words associated with pricing, like “cost”, “dollars”, or “discount”. This method works up to a certain level. Sure, it detects when people talk about the topic, pricing in this example. The problem is that in most cases, it also picks up false positives, a problem calledprecisionin the machine language vernacular.
For example, the word “dollar” may come up in a smalltalk discussion about family, a car rental conversation about Dollar (the company), or a financial discussion around a return-of-investment (ROI) of a software solution. The reality is that to successfully understand human language, one needs to considercontext, not just a word or a set of words, but alsowherethey appear.
The challenge: automation and scale
In conventional machine learning, computers learn to solve problems by studying examples.
For example, in the natural language understanding (NLU) discipline, computers can learn to identify, say, action items by looking at thousands of examples and gradually learning to recognize the patterns.
In machine learning jargon, this is what we callsupervised learning: the machine examines manylabeledexamples (“good” and “bad” examples) and learns what pattern constitutes a “yes”, for example: an action item.
This practice works in many cases, and in fact, we use it at Gong in many cases.
But, the challenge with this practice is that you need thousands of examples to apply it. At Gong, we proudly serve over 1,000 different customers. So, we can use supervised learning to teach the system to learn concepts that span all customers, like action items or scheduling. In such cases, we can label enough examples and train the system to identify them.
However, how would we handle the more interesting cases, where each company has its own set of (so-called domain-specific) concepts? Would Microsoft be interested only in how their sales teamsschedulemeetings (a generic concept) or (even more so) in how they position the benefits of their Office 365 solution (benefits unique to them)? Would the Google Ads business be interested just in how their sales teamsfollow up(a generic concept) or (more so) in what terms they frame how targeted traffic can help businesses (their own messaging)?
It’s impractical to teach a machine learning system to learn each such topic anew. Labeling examples would be prohibitively expensive: it would require subject matter experts to label thousands of examples, and the language usually changes over time. And, perhaps contrary to intuition, even topics that seem generic tend to vary quite substantially between companies. For example, Microsoft team members may talk about pricing of Office 365 indollars per month, whereas Salesforce may talk about the cost of its CRM solution, ina total annual fee per organization. Very different in the actual words used.
The importance of understanding conversation topics
To solve this problem, we came up with an innovative solution, covered in our patent. We wouldn’t be relying just on sets of keywords (as old-school systems did). And, we wouldn’t teach our system each topic anew. Instead, we’incept a system that automatically learns each company’s topics based on the actual conversations. Cool, right?
This allows our solution to provide each customer unique insights about their own business. Here are some of the results we’ve built on top of the core technology:
1. What differentiates the best salespeople from the rest?
Gong can scan the conversations carried out by different team members, and highlight what sets apart top performers from the rest of the pack.
This example shows one insight: in one software company’s scenario, in the first software demo, top performers spend more time discussingData & BI(a topic unique to them):

The advice is clear: ensure team members spend enough time covering this topic.
2. What deals are at risk?
Gong can show what topics that are discussed are more likely to help close a deal, and flag deals that haven’t had that discussion. In some cases, this may translate into actionable advice; in others, it may be a warning.
This example shows one observation: for one consulting company, a deal is more likely to close when the topicIndustry Coverage(a part of their consulting package) is discussed: deals in which the topic does not come up close at 16.1% probability, whereas deals in which this topic comes up close at a 26.7% probability—that’s 65% more!
Furthermore, this chart shows how this gap grows with the deal’s progression. 60 days before the deal closes, there’s barely a gap, but getting closer to deal closure, the gap widens: it’s hard to sell that solution without talking about industry coverage.
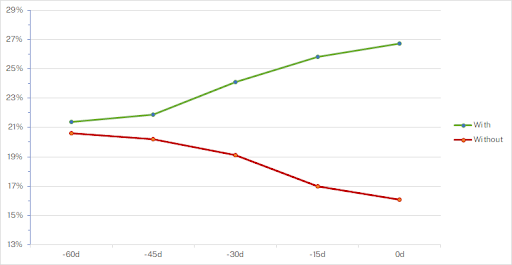
The advice here is also simple: ensure team members cover this benefit well ahead of getting to the end of the sales cycle.
3. What is this video call about?
As an executive or a manager, when you’re looking to catch up on a customer, you need to understand recent discussions with the customer. The Gong solution captures video conversations with that customer, and lets you listen to them. But, listening takes time, so Gong shows you what the video call was aboutbeforelistening to it.
This is an example of the topics that came up in a call. Anyone who hasn’t been in that call can determine whether it’s of interest:
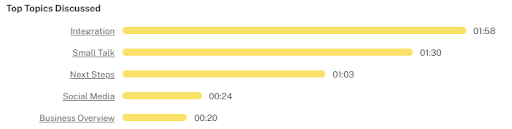
What’s more, once you drill into the call, a visual timeline shows you where each topic is, so you can quickly navigate to this area.

The technology: segment, hypothesize and iterate
Now that we’ve discussed what this technology is useful for, let’s review how it works.
The technology works in three phases: first, it segments the calls into coherent units, it then creates a rough (and far-from-the-truth) initial hypothesis as to the potential topics, and then iterates to find the “right” ones.
Here are the three steps:
1. Segment
The system first segments long sales conversations into reasonably-sized chunks. We know a conversation topic doesn’t last forever, so we break the conversation into areas that are likely to evolve around one topic. For instance, a long monologue by one participant in the meeting.
2. Hypothesize
The system then throws a hypothesis around what topics could be included within that segment. Because it doesn’t know anything about the company just yet, it really doesn’t know much. So it starts with a few common topics like smalltalk, rough pricing, and similar (these are calledpriorsin the obscure machine learning vernacular). And then creates a set ofrandomtopics (yes, you’ve heard it right! Almost all modern machine-learning systems start with some random starting point).
3. Iterate
The gist of the technology is about improving the topics from random ones to meaningful ones.
The phase starts seeing which segments match which topics. Initially, the topics are very far off (remember: they were random), but some segments would still match. The system looks at each segment and the topics that match it (even if very roughly). It then readjusts the proposed topics to to better match that segment. It then moves over to the next segment, until it’s done with all of the segments. Now, the topics might be closer: they’re based on real conversation segments. Once it’s done with this scan, it… starts again by rescanning the segments, until each topic gets closer to a set of real-life segments.
At the end of this process, which is calledGibbs Sampling, topics converge and the system declares success. Success can be measured using a metric calledperplexityin the machine learning jargon.
What’s interesting about this approach is that there is no one-to-one association between keywords and topics. The word “dollar” would often appear in multiple topics:
- If the word “dollar” comes with the company’s pricing terms (like “per user”), the segment would be labeled pricing.
- If the word “dollar” comes with non-business terms (“store”, “kids”), the segment would be labeled smalltalk.
The process is complex and there are many more details. If you’re a machine learning geek, you can find the gory details in the patent.
Making it accessible to business teams: labeling topic
Once the topics have been discovered, the fun begins:
- All historical conversations, as well as new ones, are being analyzed.
- The system finds the best topic for each segment.
- The system then computes a confidence level to assess if this topic is really a good fit for the segment.
If it is, the system marks it as compatible. If not, it is left untouched: some conversation segments, as the Seinfeld episode goes, are really “about nothing”.
Once enough segments have been identified, the system scans to see what terms are common within those segments. For example,
- APricingtopic may include the lengthy phrase “dollars per user per month”.
- ACRM(Customer Relationship Management) topic may include the term “CRM” but also the terms “account” and “opportunity” or even “closed opportunity”.
The system suggests a term or terms that are the best fit for the topic’s title, and lets a Gong reviewer change them if needed.
Voila! Now we can present the topics to business users, who care very little about the technology and much more about the actionable insight.
How we made it happen
When we started developing this technology, we wrote an initial version. We tried it over a set of initial customers. We were thrilled to see that it quickly converged into meaningful topics that we could understand:Pricing,Dashboards,Decision Process, and many more. So, the technology worked in real-life situations.
We then checked team members: indeed, there were significant differences between people. For one customer, it uncovered that under-performing salespeople were spending almost 3 minutes describing the history of that company (a topic found by the system). At another, it found out that top salespeople were carrying out smalltalk at the beginning and end of the conversation, but the bottom-performing ones were carrying it out in the middle of the conversation, presumably taking customers off track.
Once we were convinced that it provides business value, it was time to productize: we developed the engineering code behind it that runs this at scale across hundreds of customers and millions of conversations.
What’s coming
This technology is now one of the core capabilities of the Gong product, and we are continuing to enhance it.
On the product side, we’ll soon let customers change topic titles based on their understanding: not surprisingly, in some cases customers know their domain better than the machine.
On the technology front, we’ve developed an advanced version of this technology that analyzes not just the domain-specific topics in a conversation, but also the domain-specific structure of the conversation: when does a conversation typically change from a smalltalk to business? From business to next steps? It sounds related, and indeed it is. This part, however, is not included in the patent, so we can’t it yet; we’ll more once we can.
Chief Product Officer & Co-Founder at Gong
Eilon Reshef is the Co-Founder and Chief Product Officer at Gong, the leading platform in the revenue intelligence space. Since co-founding Gong in 2015, Eilon has spearheaded its product and engineering efforts, transforming how sales teams harness data to drive success. Gong uses AI to analyze sales interactions, offering actionable insights that help businesses grow revenue. Prior to Gong, Eilon co-founded Webcollage, a SaaS platform for e-commerce infrastructure. With deep expertise in product strategy and AI, Eilon is a key figure in advancing sales technology and operations.
Win more with Gong
Loading form...
Discover more from Gong
Check out the latest product information, executive insights, and selling tips and tricks, all on the Gong blog.


